Seedream 5.0
Nicht nur zeichnen, sondern zuerst denken
Seedream 5.0 verwendet eine einheitliche Architektur sowohl für Text-zu-Bild-Generierung als auch umfassende Bearbeitungsfähigkeiten und integriert gesunden Menschenverstand und Denkfähigkeiten. Verglichen mit früheren Modellen Seedream 3.0 und SeedEdit 3.0 erzielt es bedeutende Durchbrüche in multimodalen Effekten, Geschwindigkeit und Benutzerfreundlichkeit.
Schlüsseldurchbrüche
Revolutionäre Fähigkeiten
Erleben Sie die nächste Generation KI-betriebener Bilderstellung mit beispielloser Kontrolle und Qualität
Multimodale Erweiterung
Unterstützt flexibel kombinierte Text- und Bildeingaben. Ermöglicht Text-zu-Bild, Bild-zu-Bild, Bildbearbeitung, Multi-Bildbearbeitung und Gruppengenerierung mit vielfältigen kreativen Möglichkeiten.
Verbesserte Ästhetik
Unterstützt hochflexible künstlerische Stilübertragung, von Barock bis Cyberpunk. Kombinieren Sie Stile, um völlig neue Ästhetik mit herausragender visueller Anziehungskraft zu schaffen.
Logik & Verständnis
Kombiniert Weltwissen, um multimodales Eingabeverständnis zu verbessern. Nicht nur zeichnen, sondern zuerst denken - zeigt Denkfähigkeiten in Physik, Rätseln und Comics.
4K-Generierung
Adaptives Seitenverhältnis mit benutzerdefinierter Größenunterstützung. Maximale Auflösung von 2K auf 4K Ultra-High-Definition erweitert, generiert optimale Proportionen basierend auf Anweisungen oder Referenzen.
10x schnellere Geschwindigkeit
Durch innovatives Architekturdesign und extreme Destillationsbeschleunigung ist DiT-Bildgenerierung über 10x schneller als Seedream 3.0.
Branchenführend
Erreicht führende Ergebnisse in umfassenden Bewertungen, mit Schlüsselfähigkeiten an der Spitze der Branche über alle Benchmarks hinweg.
Acht Kernfähigkeiten
Von Bildgenerierung zur kreativen Engine
Erschließung neuer visueller Kreationserfahrungen über traditionelle Bildgenerierung hinaus
Präzise Bearbeitung
Herausragende Bildbearbeitungsleistung mit hochwertigen Modifikationen nur durch Texteingaben. Führt präzise Hinzufügen-, Löschen-, Modifizieren- und Ersetzen-Operationen aus, während die Gesamtbildintegrität erhalten bleibt. Perfekt für Werbedesign, E-Commerce-Retusche und Nachbearbeitung, reduziert manuelle Korrekturkosten erheblich.

Flexible Referenz
Findet die perfekte Balance zwischen Erhaltung und Kreation. Extrahiert Schlüsselinformationen aus Referenzbildern wie Charakteridentität, künstlerischen Stil oder strukturelle Merkmale und erstellt sie dann in völlig neuen Kontexten neu. Ideal für virtuelle Avatar-Erstellung, derivative Designs und sekundäre Kreation.
Visuelle Signalkontrolle
Native Integration von Canny, Depth, Mask und anderen visuellen Signalen ohne zusätzliche Modelle. Benutzer können Bildgenerierung durch einfache Skizzen, Kritzeleien oder Hilfslinien steuern. Wesentlich für Posenkontrolle, Architekturdesign und UI-Prototyp-Generierung.
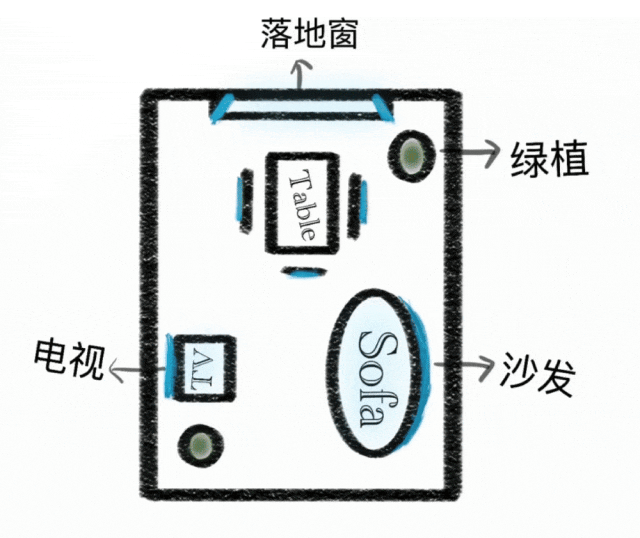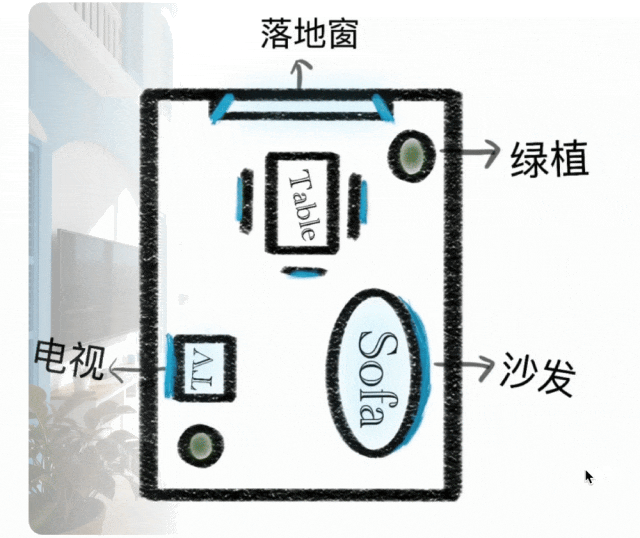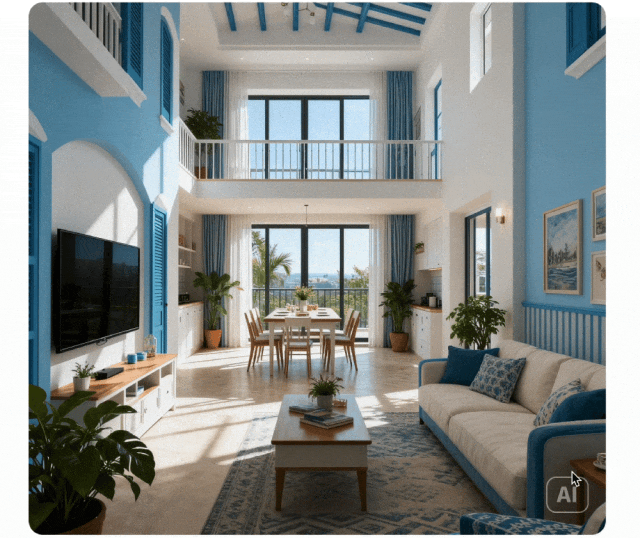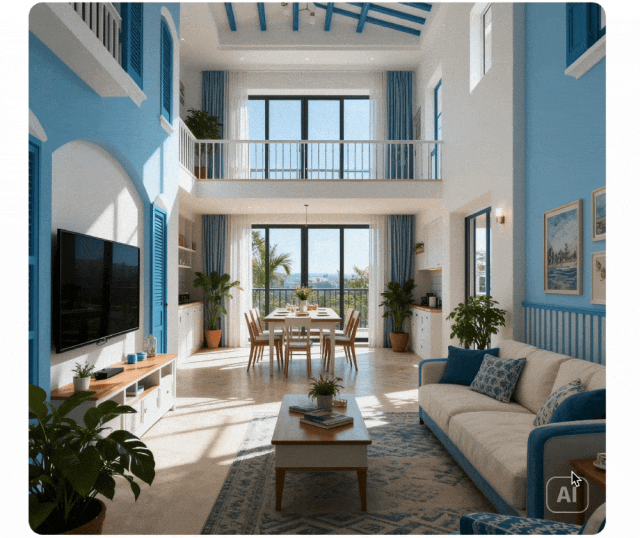

Kontextbezogenes Denken
Generierungsparadigma von einfacher Anweisungsausführung zu kontextbezogener Denkgenerierung erweitert. Versteht physikalische und zeitliche Beschränkungen, 3D-Raum und komplexe Kontexte. Behält Stilkonsistenz und feine Details in Rätseln, Kreuzworträtseln und Comic-Fortsetzungen bei.
Multi-Bild-Referenz
Unterstützt bis zu einem Dutzend Referenzbilder gleichzeitig, extrahiert Charaktermerkmale, Szenenstile und Objektstrukturen für organische Fusion. Perfekt für virtuelle Anprobe oder Kombination von Teilen zu kompletten mechanischen Strukturen bei gleichzeitiger Beibehaltung der richtigen Maßstäbe und physikalischen Kohärenz.


Multi-Bild-Ausgabe
Generiert mehrere Bilder in einer Operation mit globaler Planung und kontextueller Konsistenz. Erstellt kohärente Charaktersequenzen mit einheitlichem Stil, perfekt für Storyboards, Comic-Erstellung und zusammenhängende Design-Sets wie IP-Produkte oder Sticker-Pakete.
Erweiterte Textdarstellung
Durchbruch in der Textverarbeitung für Generierungsmodelle. Rendert nicht nur klaren Text korrekt, sondern behandelt auch Formeln, Tabellen, chemische Strukturen und statistische Diagramme. Produziert wissensreiche Inhalte wie Bildungsunterrichtsmaterialien und akademische Illustrationen.


Adaptives Verhältnis & 4K
Adaptiver Seitenverhältnis-Mechanismus passt Canvas automatisch basierend auf semantischen Bedürfnissen oder Referenzformen an. Unterstützt benutzerdefinierte Größenanpassung mit auf 4K Ultra-High-Definition erweiterter Auflösung, erreicht kommerzielle Anwendungsstandards mit ästhetischeren Kompositionen.
Technical Innovation
Unified Architecture, Superior Performance
Joint training of generation and editing enhances complex task generalization
Unified Generation & Editing
- •Integrates Seedream text-to-image and SeedEdit capabilities in one architecture
- •Perceives text prompts and reference images across different modalities
- •Maintains high-quality generation with high-consistency feature reference
Efficient Model Architecture
- •Carefully designed Diffusion Transformer with new high-compression VAE
- •10x faster training and inference compared to Seedream 3.0
- •Excellent efficiency and scalability in modality and task coverage
Enhanced Multimodal Understanding
- •Fine-tuned SeedVLM model for high-performance multimodal understanding
- •Leverages VLM's world knowledge to expand input prompts
- •Large-scale multimodal data processing pipeline
Inference Optimization
- •Adversarial distillation for stable few-step inference
- •4/8-bit mixed quantization with offline smoothing
- •Speculative decoding reduces inference latency significantly
Industry-Leading Performance
Comprehensive Evaluation Results
Leading in aesthetics, text rendering, and other core metrics
Text-to-Image Generation
Comprehensive improvements over the previous version across all dimensions. Excels in instruction following, structural stability, and visual aesthetics. Particularly enhanced dense text rendering and complex semantic understanding capabilities.
Superior image quality, natural lighting, and color coordination compared to GPT-Image-1 and other models
Single Image Editing
Deep fusion of generation and editing with comprehensive improvements over SeedEdit 3.0. Achieves balance in instruction following, reference consistency, structural integrity, and text editing. Flexibly completes complex tasks like style transfer and perspective changes while maintaining image stability.
#1 in MagicArena comprehensive Elo scoring, surpassing Seedream 4.5