Seedream 5.0
Не просто рисование, но сначала размышление
Seedream 5.0 использует унифицированную архитектуру как для генерации изображений из текста, так и для комплексных возможностей редактирования, интегрируя здравый смысл и способности к рассуждению. По сравнению с предыдущими моделями Seedream 3.0 и SeedEdit 3.0, он достигает значительных прорывов в мультимодальных эффектах, скорости и удобстве использования.
Ключевые прорывы
Революционные возможности
Испытайте следующее поколение создания изображений на базе AI с беспрецедентным контролем и качеством
Мультимодальное расширение
Гибко поддерживает комбинированные входные данные текста и изображений. Обеспечивает генерацию текст-в-изображение, изображение-в-изображение, редактирование изображений, мульти-изображенное редактирование и групповую генерацию с разнообразными творческими возможностями.
Улучшенная эстетика
Поддерживает высоко гибкий перенос художественного стиля, от барокко до киберпанка. Комбинируйте стили для создания совершенно новой эстетики с выдающейся визуальной привлекательностью.
Логика и понимание
Объединяет мировые знания для улучшения понимания мультимодальных входных данных. Не просто рисование, но сначала размышление - демонстрирует способности к рассуждению в физике, головоломках и комиксах.
Генерация 4K
Адаптивное соотношение сторон с поддержкой пользовательского размера. Максимальное разрешение расширено с 2K до 4K сверхвысокого разрешения, генерируя оптимальные пропорции на основе инструкций или ссылок.
В 10 раз быстрее
Благодаря инновационному дизайну архитектуры и экстремальному ускорению дистилляции, генерация изображений DiT более чем в 10 раз быстрее, чем Seedream 3.0.
Лидер индустрии
Достигает лидирующих результатов в комплексных оценках, с ключевыми возможностями на переднем крае индустрии во всех бенчмарках.
Восемь основных возможностей
От генерации изображений к креативному движку
Открывая новые возможности визуального творчества за пределами традиционной генерации изображений
Точное редактирование
Выдающаяся производительность редактирования изображений с высококачественными изменениями только через текстовые запросы. Точно выполняет операции добавления, удаления, изменения и замены, сохраняя общую целостность изображения. Идеально для рекламного дизайна, ретуши электронной коммерции и постпродакшена, значительно снижая затраты на ручную коррекцию.

Гибкие ссылки
Находит идеальный баланс между сохранением и созданием. Извлекает ключевую информацию из референсных изображений, такую как идентичность персонажа, художественный стиль или структурные особенности, затем воссоздает в совершенно новых контекстах. Идеально для создания виртуальных аватаров, производного дизайна и вторичного творчества.
Управление визуальными сигналами
Нативная интеграция визуальных сигналов Canny, Depth, Mask и других без дополнительных моделей. Пользователи могут направлять генерацию изображений через простые эскизы, наброски или вспомогательные линии. Необходимо для контроля поз, архитектурного дизайна и генерации прототипов UI.
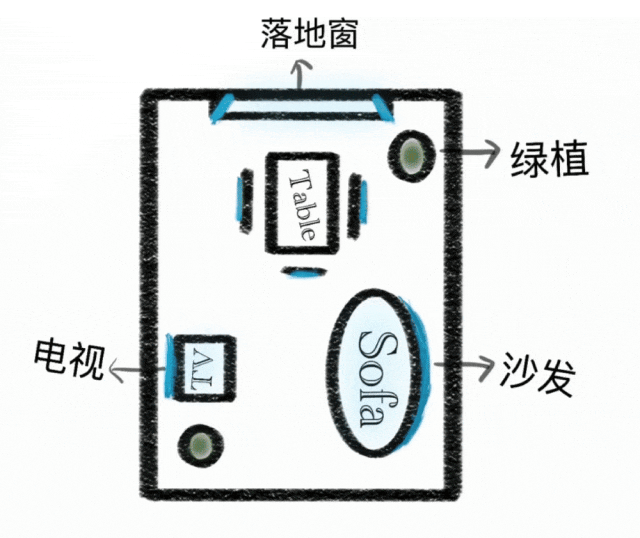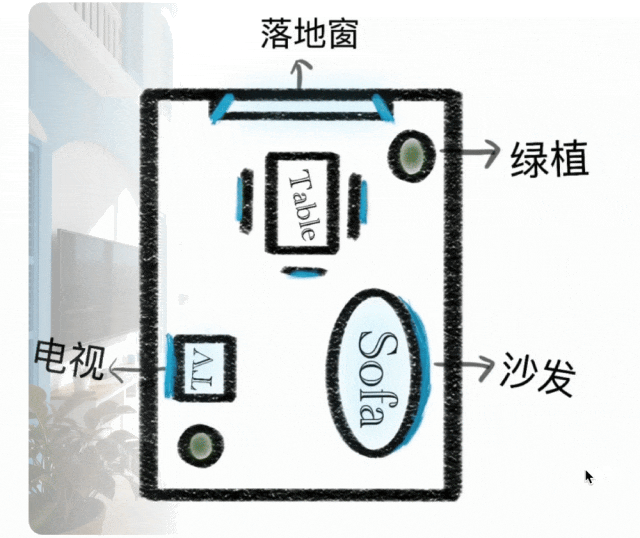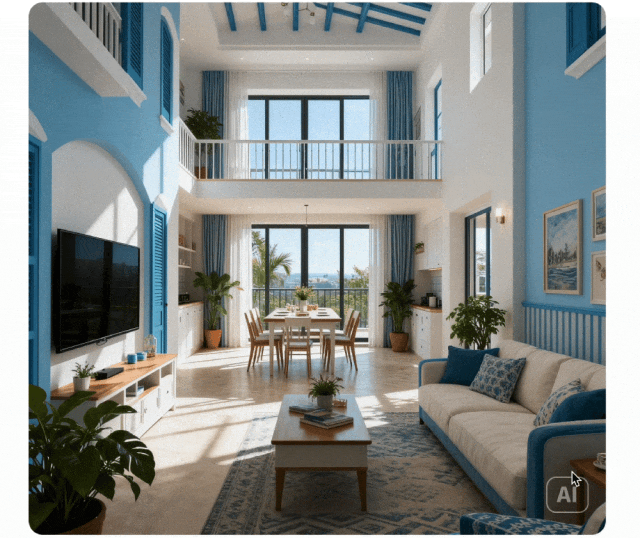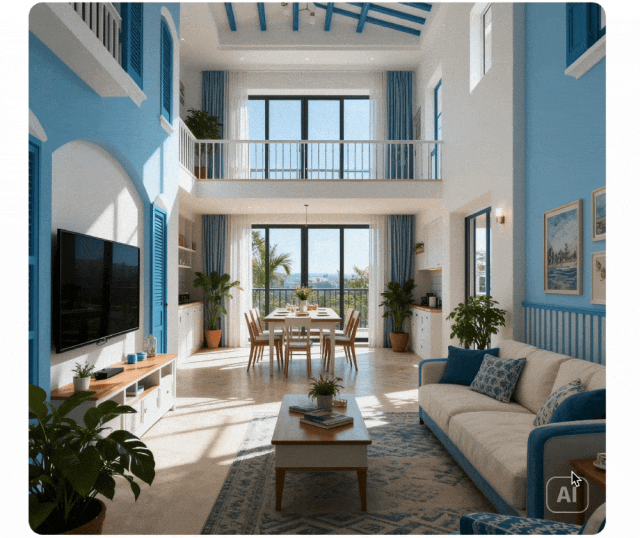

Контекстное рассуждение
Парадигма генерации расширена от простого выполнения инструкций до генерации контекстного рассуждения. Понимает физические и временные ограничения, 3D пространство и сложные контексты. Поддерживает стилистическую согласованность и мелкие детали в головоломках, кроссвордах и продолжениях комиксов.
Мульти-изображенные ссылки
Поддерживает до дюжины референсных изображений одновременно, извлекая особенности персонажей, стили сцен и структуры объектов для органического слияния. Идеально для виртуальной примерки или объединения частей в полные механические структуры при сохранении правильного масштаба и физической согласованности.


Мульти-изображенный вывод
Генерирует несколько изображений в одной операции с глобальным планированием и контекстной согласованностью. Создает согласованные последовательности персонажей с унифицированным стилем, идеально для раскадровок, создания комиксов и согласованных наборов дизайна, таких как IP продукты или наборы стикеров.
Продвинутая отрисовка текста
Прорыв в обработке текста для генеративных моделей. Не только правильно отображает четкий текст, но и обрабатывает формулы, таблицы, химические структуры и статистические диаграммы. Производит контент высокой плотности знаний, такой как образовательные курсовые работы и академические иллюстрации.


Адаптивное соотношение и 4K
Механизм адаптивного соотношения сторон автоматически настраивает холст на основе семантических потребностей или референсных форм. Поддерживает пользовательское изменение размера с разрешением, расширенным до 4K сверхвысокого разрешения, достигая стандартов коммерческого применения с более эстетичными композициями.
Technical Innovation
Unified Architecture, Superior Performance
Joint training of generation and editing enhances complex task generalization
Unified Generation & Editing
- •Integrates Seedream text-to-image and SeedEdit capabilities in one architecture
- •Perceives text prompts and reference images across different modalities
- •Maintains high-quality generation with high-consistency feature reference
Efficient Model Architecture
- •Carefully designed Diffusion Transformer with new high-compression VAE
- •10x faster training and inference compared to Seedream 3.0
- •Excellent efficiency and scalability in modality and task coverage
Enhanced Multimodal Understanding
- •Fine-tuned SeedVLM model for high-performance multimodal understanding
- •Leverages VLM's world knowledge to expand input prompts
- •Large-scale multimodal data processing pipeline
Inference Optimization
- •Adversarial distillation for stable few-step inference
- •4/8-bit mixed quantization with offline smoothing
- •Speculative decoding reduces inference latency significantly
Industry-Leading Performance
Comprehensive Evaluation Results
Leading in aesthetics, text rendering, and other core metrics
Text-to-Image Generation
Comprehensive improvements over the previous version across all dimensions. Excels in instruction following, structural stability, and visual aesthetics. Particularly enhanced dense text rendering and complex semantic understanding capabilities.
Superior image quality, natural lighting, and color coordination compared to GPT-Image-1 and other models
Single Image Editing
Deep fusion of generation and editing with comprehensive improvements over SeedEdit 3.0. Achieves balance in instruction following, reference consistency, structural integrity, and text editing. Flexibly completes complex tasks like style transfer and perspective changes while maintaining image stability.
#1 in MagicArena comprehensive Elo scoring, surpassing Seedream 4.5