Seedream 5.0
No Solo Dibujando, Sino Pensando Primero
Seedream 5.0 emplea una arquitectura unificada tanto para generación de texto a imagen como para capacidades de edición integral, integrando sentido común y habilidades de razonamiento. Comparado con modelos previos Seedream 3.0 y SeedEdit 3.0, logra avances significativos en efectos multimodales, velocidad y usabilidad.
Avances Clave
Capacidades Revolucionarias
Experimenta la próxima generación de creación de imágenes impulsada por AI con control y calidad sin precedentes
Expansión Multimodal
Soporta flexiblemente entradas combinadas de texto e imagen. Habilita texto a imagen, imagen a imagen, edición de imagen, edición de múltiples imágenes y generación grupal con posibilidades creativas diversas.
Estética Mejorada
Soporta transferencia de estilo artístico altamente flexible, desde Barroco hasta Cyberpunk. Combina estilos para crear estéticas completamente nuevas con atractivo visual sobresaliente.
Lógica y Comprensión
Combina conocimiento del mundo para mejorar la comprensión de entrada multimodal. No solo dibujando, sino pensando primero - demostrando capacidades de razonamiento en física, rompecabezas y cómics.
Generación 4K
Proporción de aspecto adaptativa con soporte de dimensionamiento personalizado. Resolución máxima expandida de 2K a 4K ultra alta definición, generando proporciones óptimas basadas en instrucciones o referencias.
10x Más Rápido
A través del diseño arquitectónico innovador y aceleración de destilación extrema, la generación de imagen DiT es más de 10 veces más rápida que Seedream 3.0.
Líder de la Industria
Logra resultados líderes en evaluaciones integrales, con capacidades clave a la vanguardia de la industria en todos los benchmarks.
Ocho Capacidades Centrales
De Generación de Imágenes a Motor Creativo
Desbloqueando nuevas experiencias de creación visual más allá de la generación de imágenes tradicional
Edición Precisa
Rendimiento sobresaliente de edición de imágenes con modificaciones de alta calidad solo a través de indicaciones de texto. Ejecuta precisamente operaciones de agregar, eliminar, modificar y reemplazar mientras mantiene la integridad general de la imagen. Perfecto para diseño publicitario, retoque de comercio electrónico y post-producción, reduciendo significativamente costos de corrección manual.

Referencia Flexible
Encuentra el equilibrio perfecto entre preservación y creación. Extrae información clave de imágenes de referencia como identidad de personaje, estilo artístico o características estructurales, luego recrea en contextos completamente nuevos. Ideal para creación de avatares virtuales, diseño derivativo y creación secundaria.
Control de Señal Visual
Integración nativa de Canny, Depth, Mask y otras señales visuales sin modelos adicionales. Los usuarios pueden guiar la generación de imágenes a través de bocetos simples, garabatos o líneas auxiliares. Esencial para control de poses, diseño arquitectónico y generación de prototipos de UI.
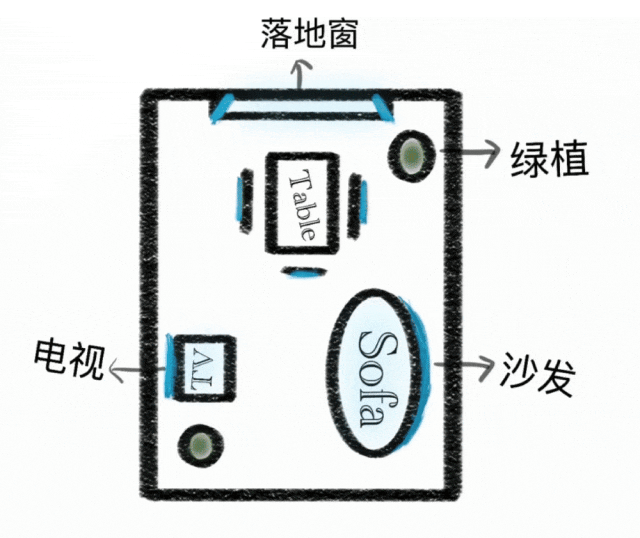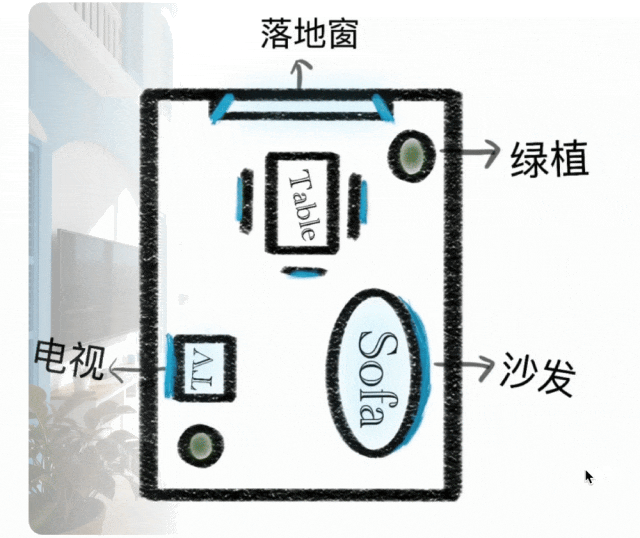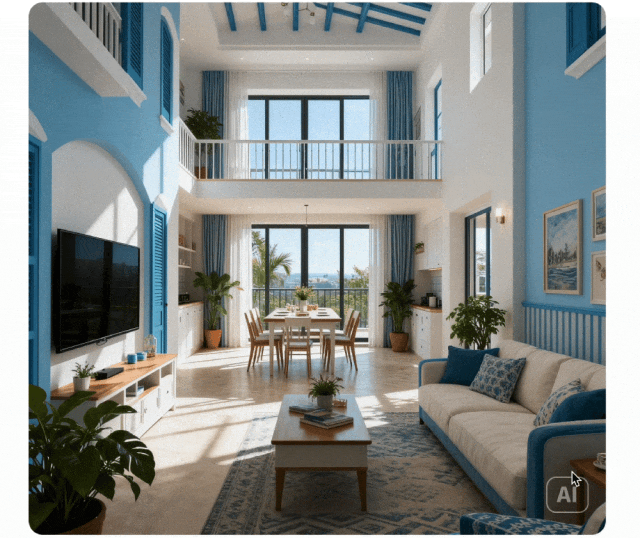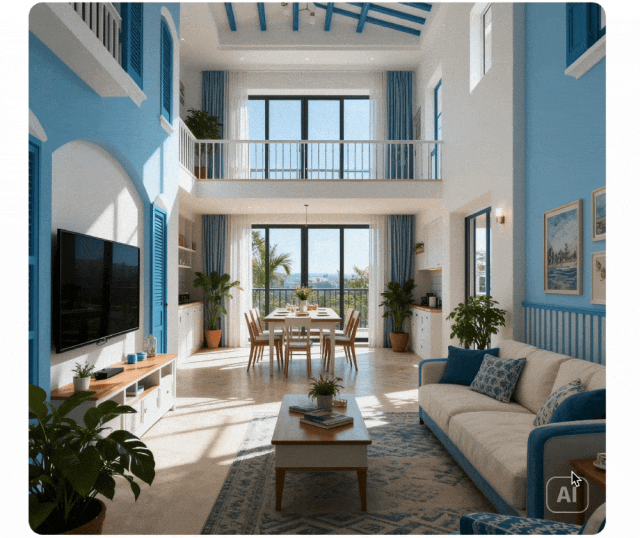

Razonamiento en Contexto
Paradigma de generación expandido desde ejecución de instrucciones simple hasta generación de razonamiento en contexto. Entiende restricciones físicas y temporales, espacio 3D y contextos complejos. Mantiene consistencia de estilo y detalles finos en rompecabezas, crucigramas y continuaciones de cómics.
Referencia de Múltiples Imágenes
Soporta hasta una docena de imágenes de referencia simultáneamente, extrayendo características de personajes, estilos de escena y estructuras de objetos para fusión orgánica. Perfecto para prueba virtual o combinación de partes en estructuras mecánicas completas mientras mantiene escala apropiada y coherencia física.


Salida de Múltiples Imágenes
Genera múltiples imágenes en una operación con planificación global y consistencia contextual. Crea secuencias de personajes coherentes con estilo unificado, perfecto para storyboards, creación de cómics y conjuntos de diseño cohesivos como productos IP o paquetes de stickers.
Renderizado de Texto Avanzado
Avance en procesamiento de texto para modelos de generación. No solo renderiza texto claro correctamente sino que también maneja fórmulas, tablas, estructuras químicas y gráficos estadísticos. Produce contenido de alta densidad de conocimiento como material educativo e ilustraciones académicas.


Proporción Adaptativa y 4K
Mecanismo de proporción de aspecto adaptativo ajusta automáticamente el lienzo basado en necesidades semánticas o formas de referencia. Soporta dimensionamiento personalizado con resolución expandida a 4K ultra alta definición, logrando estándares de aplicación comercial con composiciones más estéticas.
Technical Innovation
Unified Architecture, Superior Performance
Joint training of generation and editing enhances complex task generalization
Unified Generation & Editing
- •Integrates Seedream text-to-image and SeedEdit capabilities in one architecture
- •Perceives text prompts and reference images across different modalities
- •Maintains high-quality generation with high-consistency feature reference
Efficient Model Architecture
- •Carefully designed Diffusion Transformer with new high-compression VAE
- •10x faster training and inference compared to Seedream 3.0
- •Excellent efficiency and scalability in modality and task coverage
Enhanced Multimodal Understanding
- •Fine-tuned SeedVLM model for high-performance multimodal understanding
- •Leverages VLM's world knowledge to expand input prompts
- •Large-scale multimodal data processing pipeline
Inference Optimization
- •Adversarial distillation for stable few-step inference
- •4/8-bit mixed quantization with offline smoothing
- •Speculative decoding reduces inference latency significantly
Industry-Leading Performance
Comprehensive Evaluation Results
Leading in aesthetics, text rendering, and other core metrics
Text-to-Image Generation
Comprehensive improvements over the previous version across all dimensions. Excels in instruction following, structural stability, and visual aesthetics. Particularly enhanced dense text rendering and complex semantic understanding capabilities.
Superior image quality, natural lighting, and color coordination compared to GPT-Image-1 and other models
Single Image Editing
Deep fusion of generation and editing with comprehensive improvements over SeedEdit 3.0. Achieves balance in instruction following, reference consistency, structural integrity, and text editing. Flexibly completes complex tasks like style transfer and perspective changes while maintaining image stability.
#1 in MagicArena comprehensive Elo scoring, surpassing Seedream 4.5