Seedream 5.0
描くだけでなく、まず考える
Seedream 5.0は、テキストから画像生成と包括的編集機能の両方に統一アーキテクチャを採用し、常識と推論能力を統合しています。従来モデルSeedream 3.0およびSeedEdit 3.0と比較して、マルチモーダル効果、速度、使いやすさで大幅な飛躍を達成しています。
主要な革新
革命的機能
前例のない制御と品質を持つAI駆動画像作成の次世代を体験
マルチモーダル拡張
テキストと画像入力の組み合わせを柔軟にサポート。テキストから画像、画像から画像、画像編集、マルチ画像編集、グループ生成を多様なクリエイティブ可能性とともに実現。
美学強化
バロックからサイバーパンクまで、高度に柔軟な芸術的スタイル転送をサポート。スタイルを組み合わせて、優れた視覚的魅力を持つ完全に新しい美学を創造。
論理と理解
世界知識を組み合わせてマルチモーダル入力理解を強化。描くだけでなくまず考える - 物理学、パズル、コミックにおける推論能力を実証。
4K生成
カスタムサイジングサポート付きの適応アスペクト比。最大解像度を2Kから4K超高精細に拡張し、指示や参照に基づいて最適比率を生成。
10倍高速
革新的アーキテクチャ設計と極限蒸留加速により、DiT画像生成がSeedream 3.0より10倍以上高速。
業界リーディング
包括評価で業界最先端の結果を達成。すべてのベンチマークで業界の最前線に立つ主要機能。
8つのコア機能
画像生成からクリエイティブエンジンまで
従来の画像生成を超えた新しい視覚創造体験を解放
精密編集
テキストプロンプトのみで高品質修正を実現する優れた画像編集性能。画像全体の整合性を保ちながら、追加、削除、修正、置換操作を正確に実行。広告デザイン、EC修正、ポストプロダクションに最適、手動修正コストを大幅削減。

柔軟な参照
保存と創造の完璧なバランスを発見。キャラクターのアイデンティティ、芸術スタイル、構造的特徴など参照画像から重要情報を抽出し、完全に新しいコンテキストで再創造。バーチャルアバター作成、派生デザイン、二次創作に理想的。
視覚信号制御
追加モデル不要でCanny、Depth、Maskなどの視覚信号をネイティブ統合。シンプルなスケッチ、落書き、補助線を通じて画像生成をガイド。ポーズ制御、建築設計、UIプロトタイプ生成に不可欠。
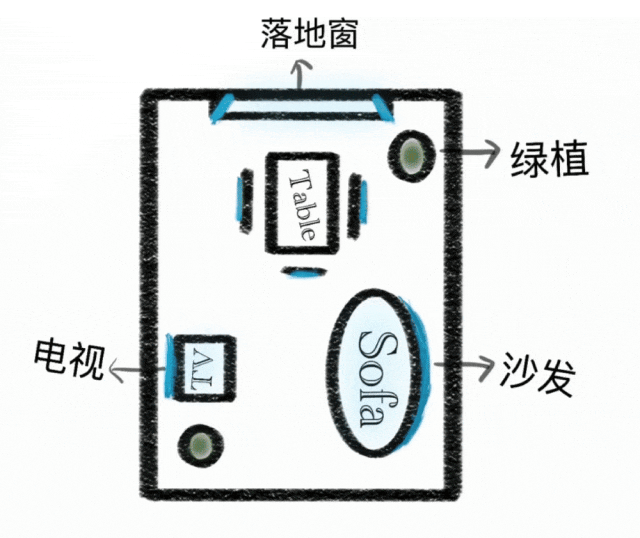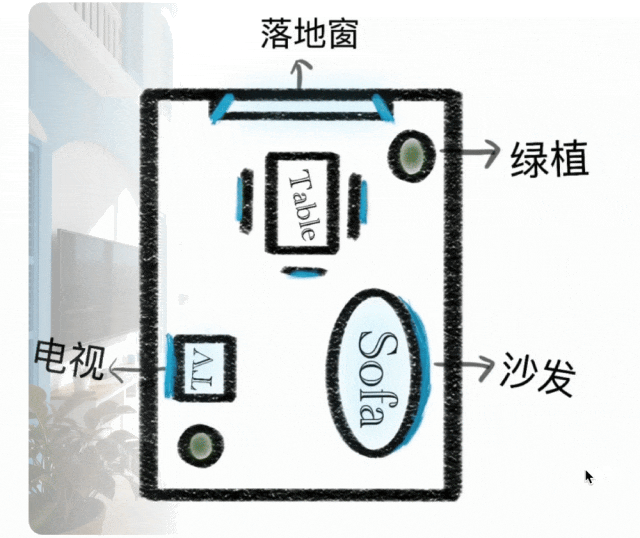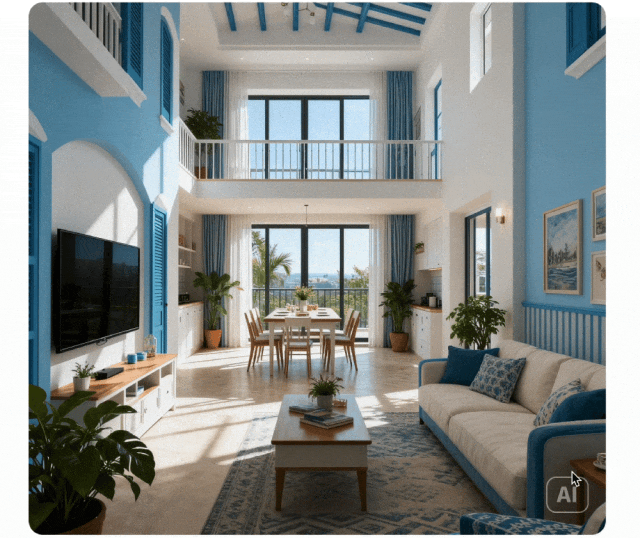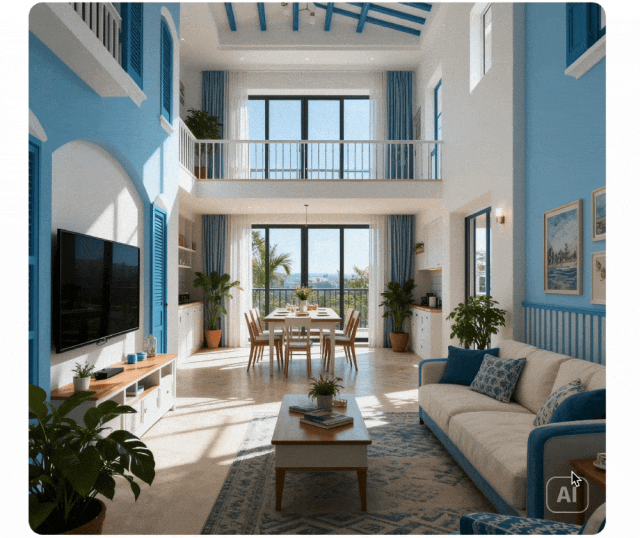

文脈内推論
シンプルな指示実行から文脈内推論生成へと生成パラダイムを拡張。物理的・時間的制約、3D空間、複雑なコンテキストを理解。パズル、クロスワード、コミック継続において、スタイル一貫性と細部を維持。
マルチ画像参照
同時に最大12の参照画像をサポートし、キャラクター特徴、シーンスタイル、オブジェクト構造を抽出して有機的融合。適切なスケールと物理的一貫性を保ちながら、バーチャル試着や部品を完全な機械構造に結合するのに最適。


マルチ画像出力
グローバル計画と文脈一貫性で一回の操作で複数画像を生成。統一スタイルで一貫性のあるキャラクターシーケンスを作成、ストーリーボード、コミック作成、IP製品やステッカーパックなど一貫性のあるデザインセットに最適。
高度テキストレンダリング
生成モデルのテキスト処理における画期的進展。明確なテキストを正確にレンダリングするだけでなく、数式、表、化学構造、統計チャートも処理。教育教材や学術イラストなど高知識密度コンテンツを生成。


適応比率・4K
適応アスペクト比メカニズムが意味的ニーズや参照形状に基づいてキャンバスを自動調整。4K超高精細への解像度拡張でカスタムサイジングをサポート、より美的な構成で商用アプリケーション基準を達成。
Technical Innovation
Unified Architecture, Superior Performance
Joint training of generation and editing enhances complex task generalization
Unified Generation & Editing
- •Integrates Seedream text-to-image and SeedEdit capabilities in one architecture
- •Perceives text prompts and reference images across different modalities
- •Maintains high-quality generation with high-consistency feature reference
Efficient Model Architecture
- •Carefully designed Diffusion Transformer with new high-compression VAE
- •10x faster training and inference compared to Seedream 3.0
- •Excellent efficiency and scalability in modality and task coverage
Enhanced Multimodal Understanding
- •Fine-tuned SeedVLM model for high-performance multimodal understanding
- •Leverages VLM's world knowledge to expand input prompts
- •Large-scale multimodal data processing pipeline
Inference Optimization
- •Adversarial distillation for stable few-step inference
- •4/8-bit mixed quantization with offline smoothing
- •Speculative decoding reduces inference latency significantly
Industry-Leading Performance
Comprehensive Evaluation Results
Leading in aesthetics, text rendering, and other core metrics
Text-to-Image Generation
Comprehensive improvements over the previous version across all dimensions. Excels in instruction following, structural stability, and visual aesthetics. Particularly enhanced dense text rendering and complex semantic understanding capabilities.
Superior image quality, natural lighting, and color coordination compared to GPT-Image-1 and other models
Single Image Editing
Deep fusion of generation and editing with comprehensive improvements over SeedEdit 3.0. Achieves balance in instruction following, reference consistency, structural integrity, and text editing. Flexibly completes complex tasks like style transfer and perspective changes while maintaining image stability.
#1 in MagicArena comprehensive Elo scoring, surpassing Seedream 4.5