Seedream 5.0
不只是绘画,而是先思考
Seedream 5.0 采用统一架构,同时支持文本生成图像和全面编辑功能,融入常识和推理能力。相比之前的模型 Seedream 3.0 和 SeedEdit 3.0,在多模态效果、速度和可用性方面实现重大突破。
关键突破
革命性功能
体验下一代 AI 驱动的图像创作,拥有前所未有的控制力和质量
多模态扩展
灵活支持文本和图像的组合输入。实现文本生成图像、图像转图像、图像编辑、多图编辑和组合生成,创意可能性多样。
增强美学
支持高度灵活的艺术风格转换,从巴洛克到赛博朋克。结合风格创造全新美学,具有出色的视觉吸引力。
逻辑与理解
结合世界知识增强多模态输入理解。不只是绘画,而是先思考 - 在物理、谜题和漫画中展现推理能力。
4K 生成
自适应宽高比,支持自定义尺寸。最大分辨率从 2K 扩展到 4K 超高清,根据指令或参考生成最佳比例。
10倍更快速度
通过创新架构设计和极限蒸馏加速,DiT 图像生成比 Seedream 3.0 快 10 倍以上。
行业领先
在综合评估中取得领先结果,核心能力在所有基准测试中处于行业前沿。
八大核心能力
从图像生成到创意引擎
解锁超越传统图像生成的新视觉创作体验
精确编辑
出色的图像编辑性能,仅通过文本提示即可进行高质量修改。精确执行增加、删除、修改和替换操作,同时保持整体图像完整性。适用于广告设计、电商修图和后期制作,大幅降低手动校正成本。

灵活参考
在保留和创造之间找到完美平衡。从参考图像中提取关键信息,如人物身份、艺术风格或结构特征,然后在全新环境中重新创作。适用于虚拟头像创建、衍生设计和二次创作。
视觉信号控制
原生集成 Canny、深度、遮罩等视觉信号,无需额外模型。用户可以通过简单素描、涂鸦或辅助线指导图像生成。适用于姿势控制、建筑设计和 UI 原型生成。
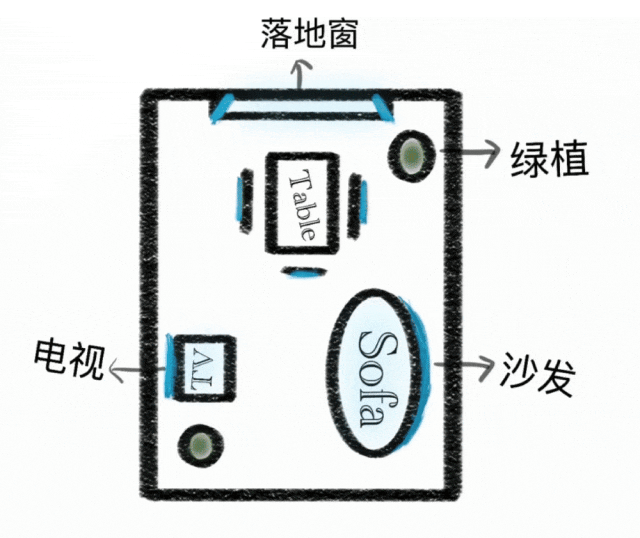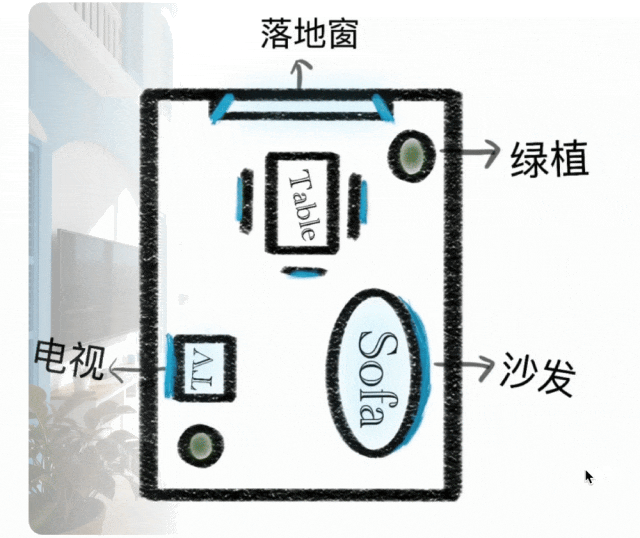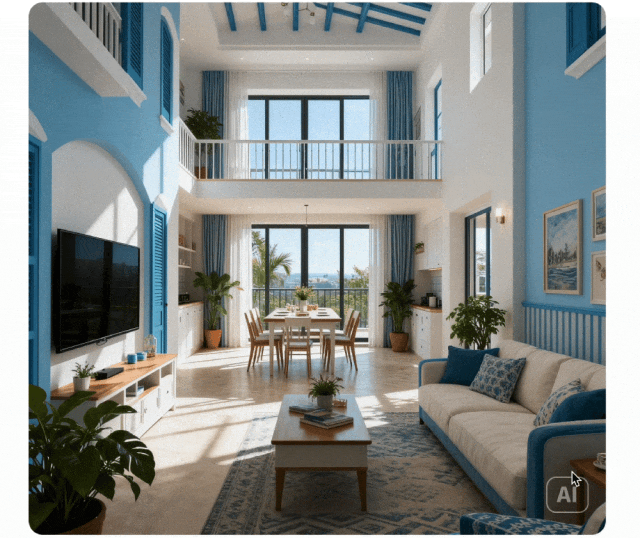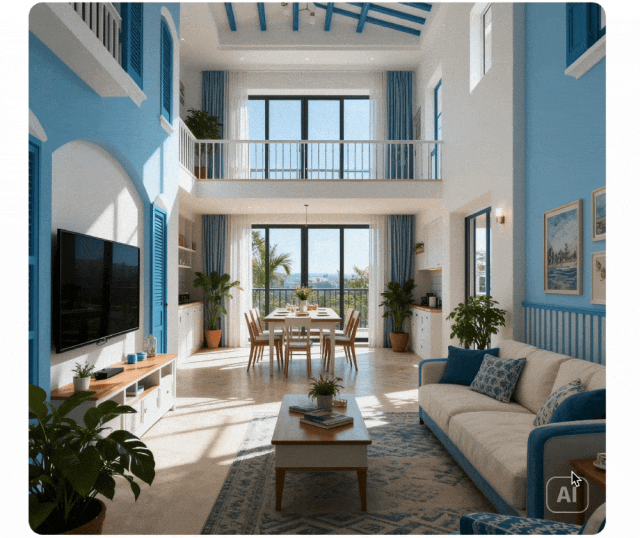

上下文推理
生成范式从简单指令执行扩展到上下文推理生成。理解物理和时间约束、3D 空间和复杂上下文。在谜题、填字游戏和漫画续集中保持风格一致性和精细细节。
多图参考
同时支持多达十几张参考图像,提取人物特征、场景风格和物体结构进行有机融合。适用于虚拟试穿或将部件组合成完整机械结构,同时保持适当比例和物理一致性。


多图输出
一次操作生成多张图像,具有全局规划和上下文一致性。创建具有统一风格的连贯人物序列,适用于故事板、漫画创作和 IP 产品或贴纸包等连贯设计套装。
高级文本渲染
生成模型在文本处理方面的突破。不仅正确渲染清晰文本,还处理公式、表格、化学结构和统计图表。生成高知识密度内容,如教育课件和学术插图。


自适应比例与 4K
自适应宽高比机制根据语义需求或参考形状自动调整画布。支持自定义尺寸,分辨率扩展到 4K 超高清,达到商业应用标准,构图更具美感。
Technical Innovation
Unified Architecture, Superior Performance
Joint training of generation and editing enhances complex task generalization
Unified Generation & Editing
- •Integrates Seedream text-to-image and SeedEdit capabilities in one architecture
- •Perceives text prompts and reference images across different modalities
- •Maintains high-quality generation with high-consistency feature reference
Efficient Model Architecture
- •Carefully designed Diffusion Transformer with new high-compression VAE
- •10x faster training and inference compared to Seedream 3.0
- •Excellent efficiency and scalability in modality and task coverage
Enhanced Multimodal Understanding
- •Fine-tuned SeedVLM model for high-performance multimodal understanding
- •Leverages VLM's world knowledge to expand input prompts
- •Large-scale multimodal data processing pipeline
Inference Optimization
- •Adversarial distillation for stable few-step inference
- •4/8-bit mixed quantization with offline smoothing
- •Speculative decoding reduces inference latency significantly
Industry-Leading Performance
Comprehensive Evaluation Results
Leading in aesthetics, text rendering, and other core metrics
Text-to-Image Generation
Comprehensive improvements over the previous version across all dimensions. Excels in instruction following, structural stability, and visual aesthetics. Particularly enhanced dense text rendering and complex semantic understanding capabilities.
Superior image quality, natural lighting, and color coordination compared to GPT-Image-1 and other models
Single Image Editing
Deep fusion of generation and editing with comprehensive improvements over SeedEdit 3.0. Achieves balance in instruction following, reference consistency, structural integrity, and text editing. Flexibly completes complex tasks like style transfer and perspective changes while maintaining image stability.
#1 in MagicArena comprehensive Elo scoring, surpassing Seedream 4.5